¿Quieres aprender a optimizar el SEO On Page de tu web como un profesional? Screaming Frog Seo Spider es la mejor herramienta del mundo para el análisis On Page de las urls de una web. Es un scrapper, una araña que te revisa la web de arriba a abajo, enlace por enlace, y te la analiza, mostrándote todo lo que puedas querer saber de cada una de las páginas.
Fórmate como experto en SEO técnico con los mejores referentes del sector
Máster SEOTe indica desde cuántos caracteres de texto tiene cada página hasta, sus links internos y externos, sus metadatos… Te lo examina todo, por lo que es perfecta para corregir errores, mejorar la arquitectura de tu web y así mejorar su posicionamiento orgánico.
En esta guía de Screaming Frog te explico paso a paso cómo funciona la herramienta y todo lo que puedes analizar.
1. Cómo instalar Screaming Frog
Screaming Frog es una herramienta imprescindible y, a diferencia de otras, es una aplicación de escritorio, no online, por lo que tendrás que descargártela en tu ordenador desde el apartado SEO Spider del menú principal de su web para poder usarla.
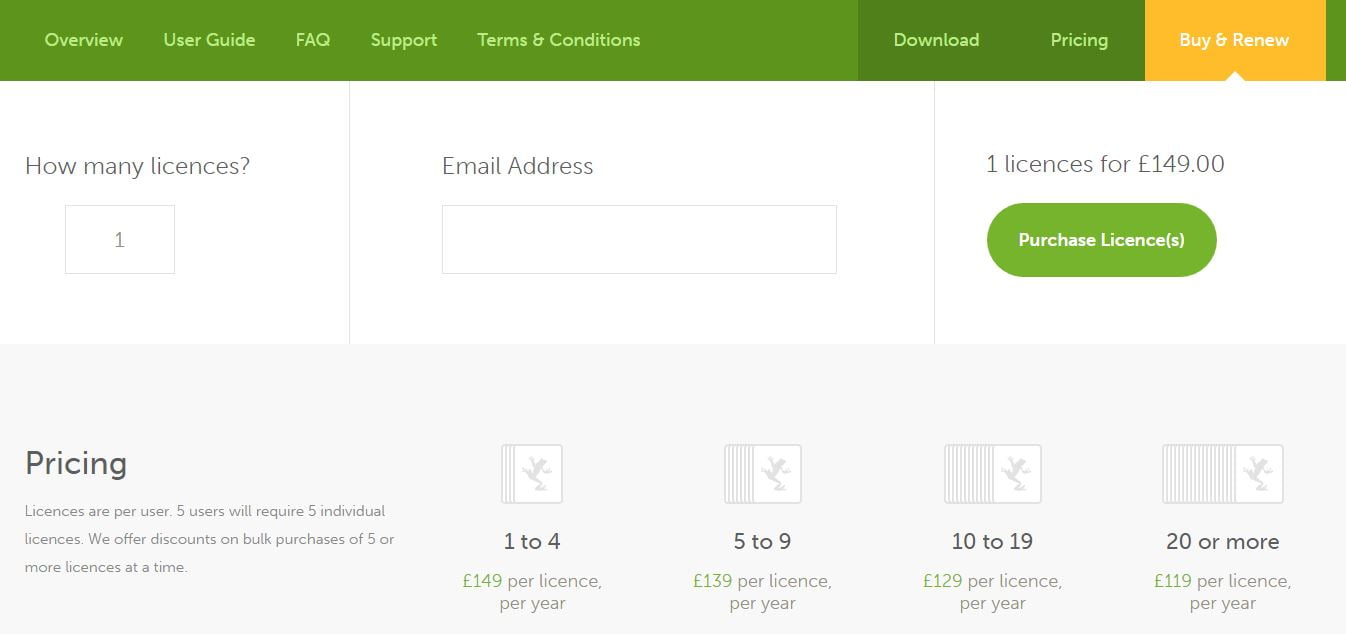
Tiene una versión gratuita con la que puedes analizar hasta 500 urls, pero para poder guardar proyectos y acceder a todas sus funcionalidades deberás comprar una licencia anual, que cuesta 149 libras, al cambio actualmente unos 172 euros. Son menos de 15 euros al mes y vale la pena.
Una vez hayamos decidido qué versión vamos a usar, procederemos a la descarga.
Para este tutoría de Streaming Frog, la versión de la herramienta es la 7.2. Es posible que te pida actualizar el JavaScript de tu PC para poder ponerla en marcha.
Bien, una vez lo abrimos nos encontramos con su interfaz principal, que como puedes ver es bastante austera, la verdad.

2. El menú superior de Screaming Frog
Vamos a comenzar viendo lo que ofrece el menú superior del modo que aparece por defecto, que es Spider, el de la araña.
En el menú “File” podemos abrir archivos de cualquier ubicación, volver a abrir los recientes y guardarlos. También podemos “grabar” la configuración que en esos momentos tengamos como la que aparecerá por defecto siempre o bien borrar la existente. Asimismo se puede limpiar el «crawl» o rastreo reciente y, por último, salir de la herramienta.
En “Configuration” tenemos en primer lugar el submenú “Spider”, que nos da la opción de indicar cómo queremos que actúe la araña sobre las webs que queramos analizar.

Hay múltiples factores que podemos personalizar en función de lo que nos interese ver o analizar en cada caso.
Aquí tenemos, por ejemplo, dentro de HTTP Header, la opción User Agent, que nos permite decidir con qué tipo de “araña” vamos a trabajar.
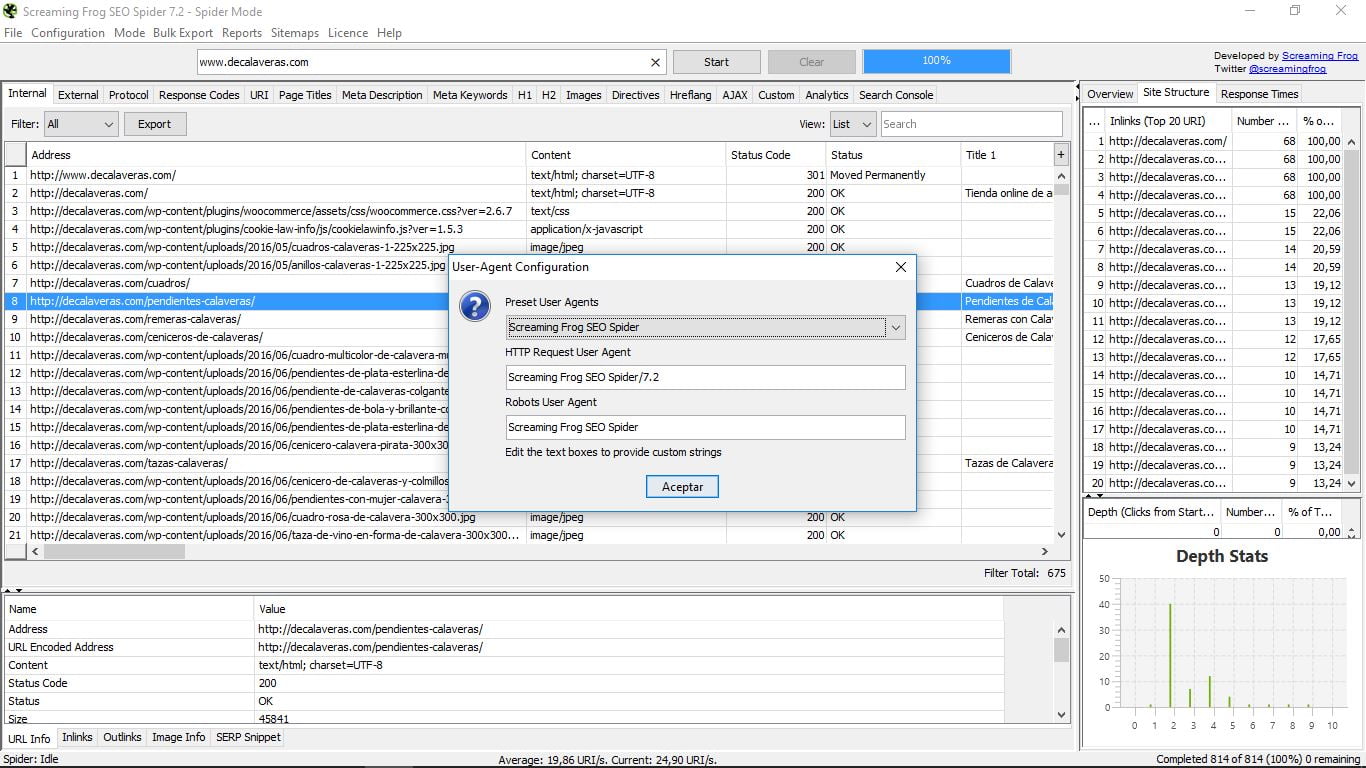
Esto es útil para cuando el hosting donde tenemos alojada nuestra web bloquea el acceso de la araña de Screaming Frog y no podemos usar la herramienta. Bastará con usar el simulador del robot de Google para solucionar el problema.
En “Robots.txt” podemos configurar y también personalizar cómo se comportará la araña con este tipo de archivos.
En el resto de opciones tenemos funciones muy diversas de configuración, entre ellas la conexión con las APIs de Analytics y Search Console, o una visualización del interfaz un poco más amigable, al estilo Windows. Trabajaremos en esta guía de Screaming Frog con ella por ser más ordenada e intuitiva.
En “Mode” escogeremos qué función principal queremos usar: araña, lista o SERP. Luego las explicaremos con detalle, ya que el menú general varía en cada caso.
“Bulk Export” nos permite exportar de forma masiva en documentos de formato CSV los informes sobre links entrantes o salientes, imágenes, anchor text, así como personalizar filtros; mientras que en “Reports” accederemos a un resumen del rastreo e informes de errores en distintos parámetros.
“Sitemaps” nos da la opción de crear un mapa del sitio, y también de sus imágenes. Estas opciones son poco habituales ya, puesto que la mayoría de las herramientas para la gestión de las webs la llevan incluida. Si no es el caso, aquí puedes descargarlos y enviarlos a Google Search Console.
“Licence” es el enlace para pagar por la versión “pro” y para introducir la clave una vez nos hemos suscrito.
En “Help”, por último, tenemos una guía de usuario, unas preguntas frecuentes, un contacto de soporte y feedback, una búsqueda y autocheck para actualizaciones de la herramienta, un depurador debug y una página de “Acerca de”. Ayuda que esperamos que no te haga falta usar tras leer este tutorial 😉
3. El modo Spider
Estando en esta modalidad de la herramienta, si introducimos la url de una web nos hará una completa auditoría del sitio.
Hay una barra de progreso que indica en porcentaje el avance del “escaneo” de todas las páginas de la web en cuestión, como puedes ver en la siguiente captura. Cabe la opción de detener el proceso y luego reanudarlo o directamente borrar la consulta.

Vamos a ver las entrañas de la propia web de Screaming Frog.
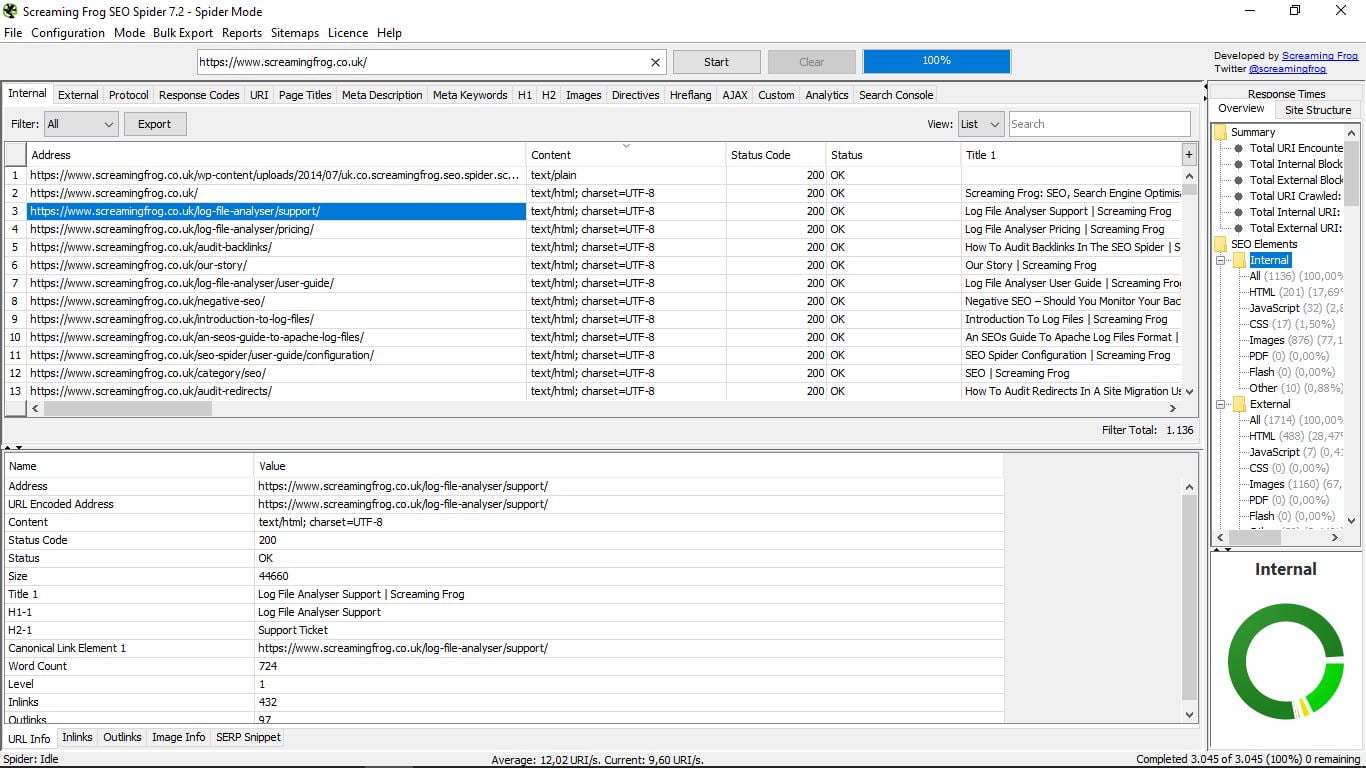
Cuando ha finalizado la tarea de la araña (tardará más o menos en función del tamaño de la web) sabremos el número total de las páginas que forman parte de su sitio. En este caso son 3.045. De todas ellas podemos ver ahora un sinfín de datos.

Tenemos la opción por defecto de mostrar todo, pero en «Filter» (arriba a la izquierda de la ventana de los resultados) se pueden filtrar las páginas según el tipo de contenido que sean: html, JavaScript, CSS, pdf, imágenes, flash… Y cualquiera de estas búsquedas selectivas, o la total, pueden exportarse (botón Export)
A la derecha, en «View» podemos seleccionar la vista por lista o por árbol de carpetas, así como realizar en la barra «Search» una búsqueda por palabras para localizar una url concreta.
Dentro de la tabla también se pueden ordenar los resultados por el tipo de contenido, su código de estado y por su title.
Cuando pinchamos en una url en concreto, vemos que abajo podemos ampliar la ventana donde nos da toda la información sobre la misma:
Debajo de esa misma ventana tenemos otro submenú que permite elegir qué tipo de datos muestra:
- URL info, que es la que sale por defecto y aporta la dirección, el tipo de contenido, el estado, el tamaño, el title, el primero de los H2, el enlace canónico, el número de palabras, el nivel, el número de enlaces internos y externos.
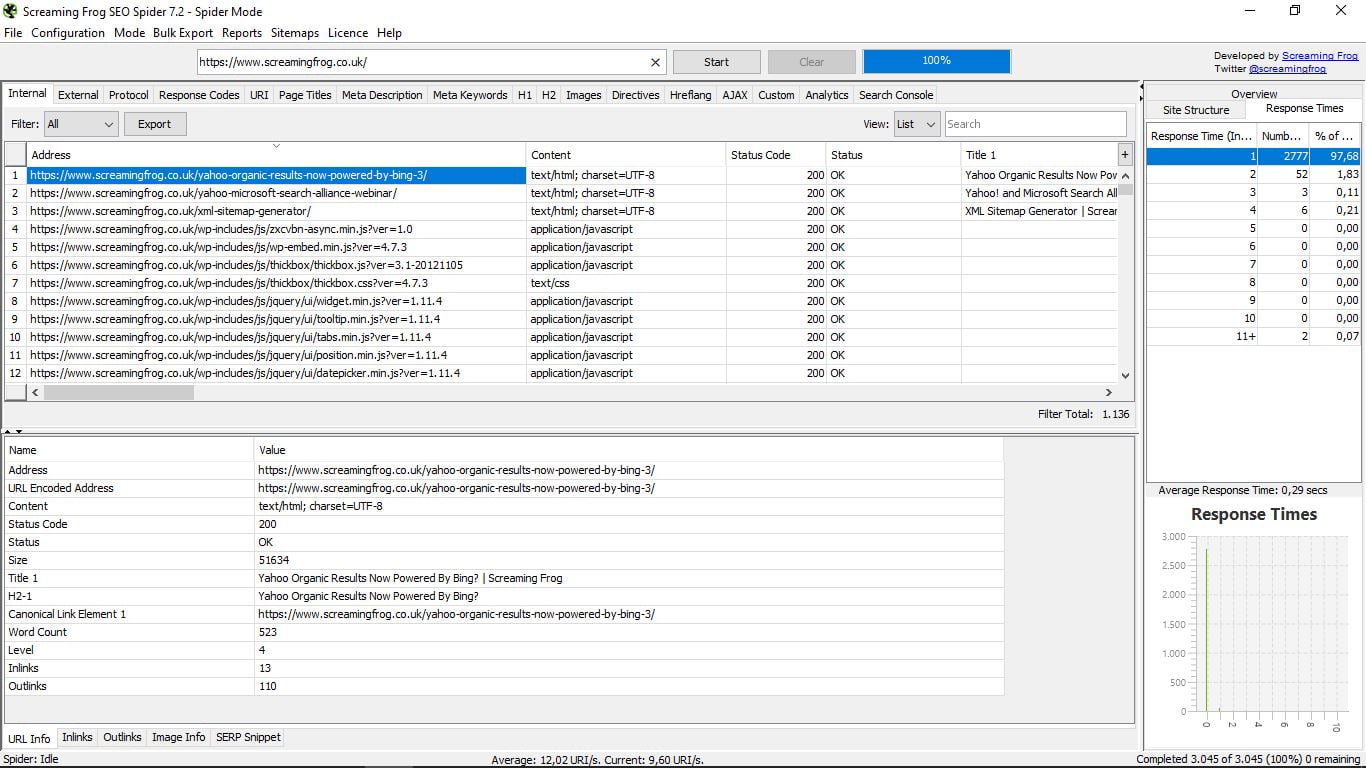
- Inlinks (enlaces internos), que nos muestra el tipo de enlace, de dónde parte y adónde dirige, el anchor text, el Alt text (si lo tienen) y si son Follow o no.
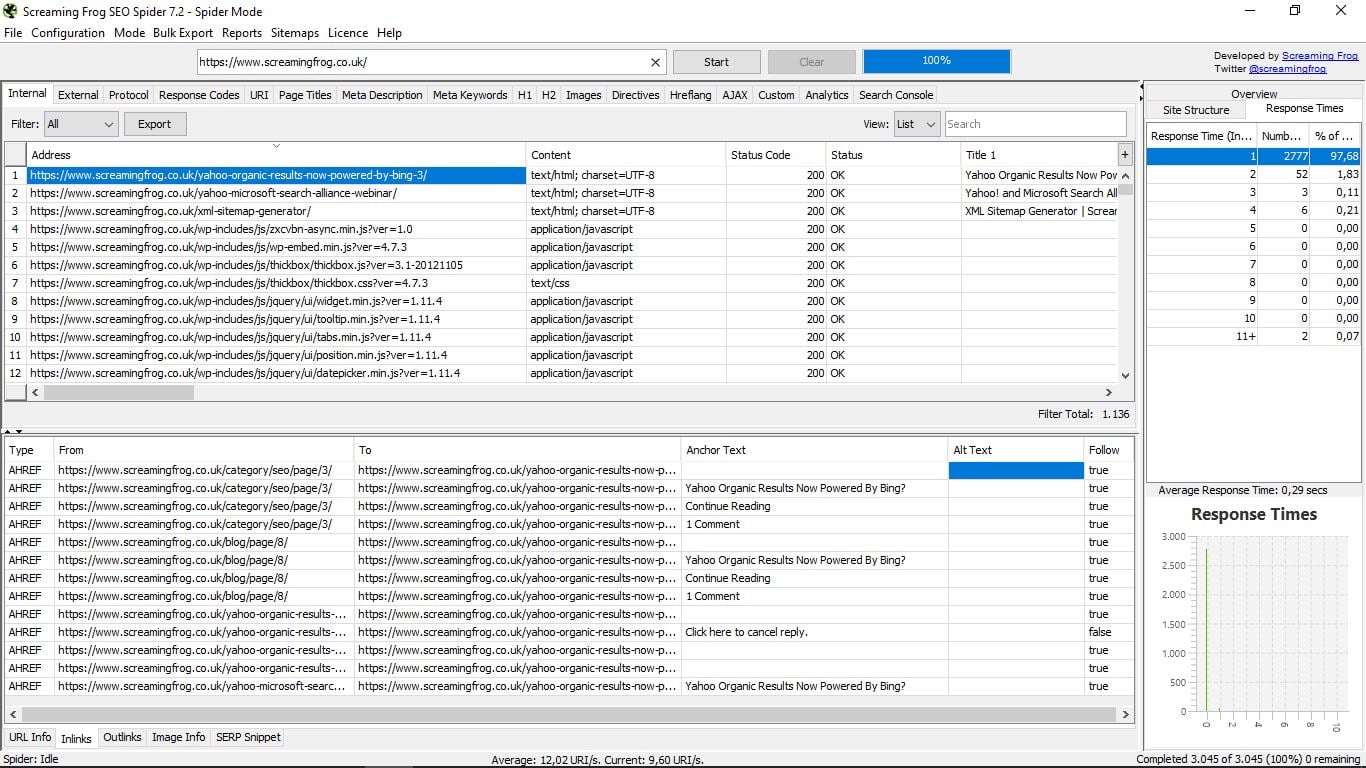
- Outlinks. Exactamente la misma información que la de Inlinks, pero para los enlaces externos.
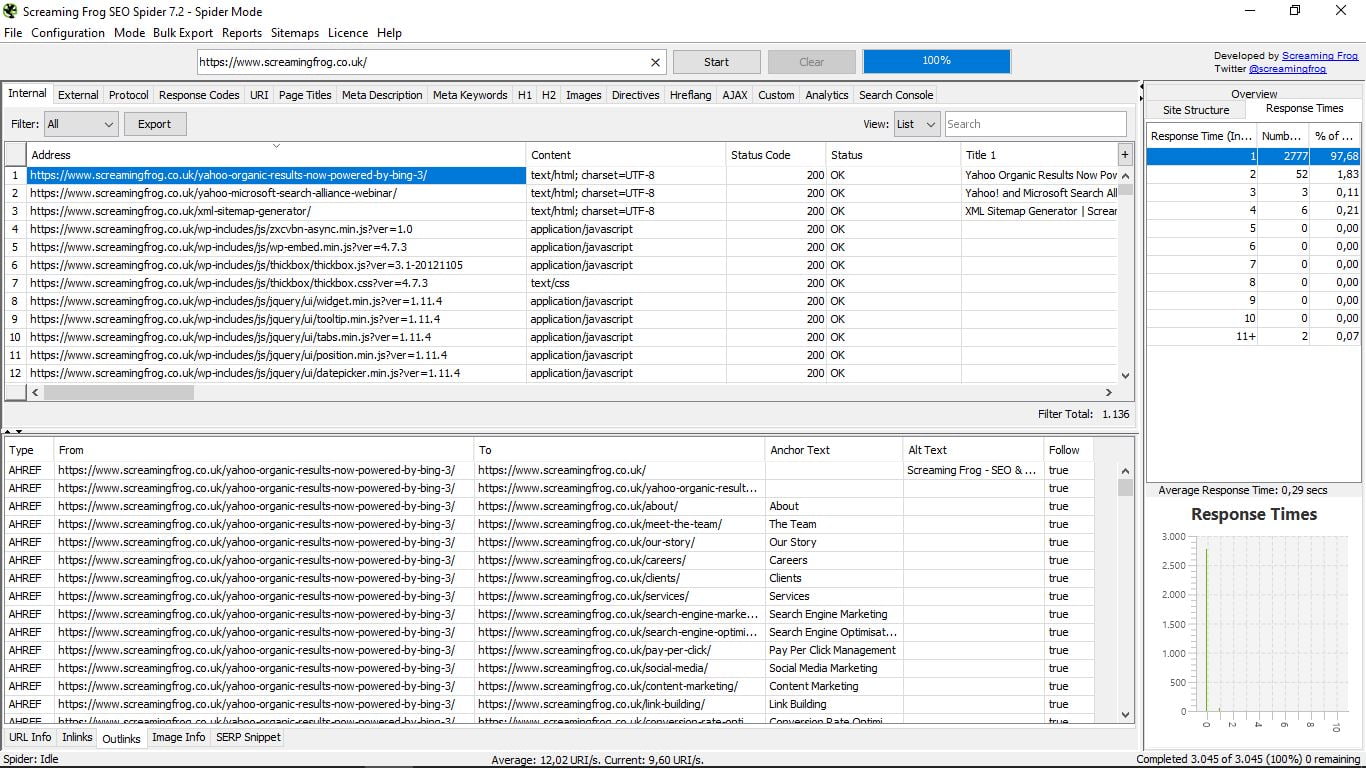
- Image Info: información de las imágenes enlazadas que contiene esa página, hacia dónde apunta y el Alt Text.
- SERP Snippet. Visualiza cómo se ve en las búsquedas de Google esa página. Permite verlo para escritorio, móvil y tablet e incluye un simulador, con los datos de los caracteres y los píxeles para los title y las descripciones, las keywords, los Rich Snippets (Reviews, gente, eventos), con o sin estrellas…
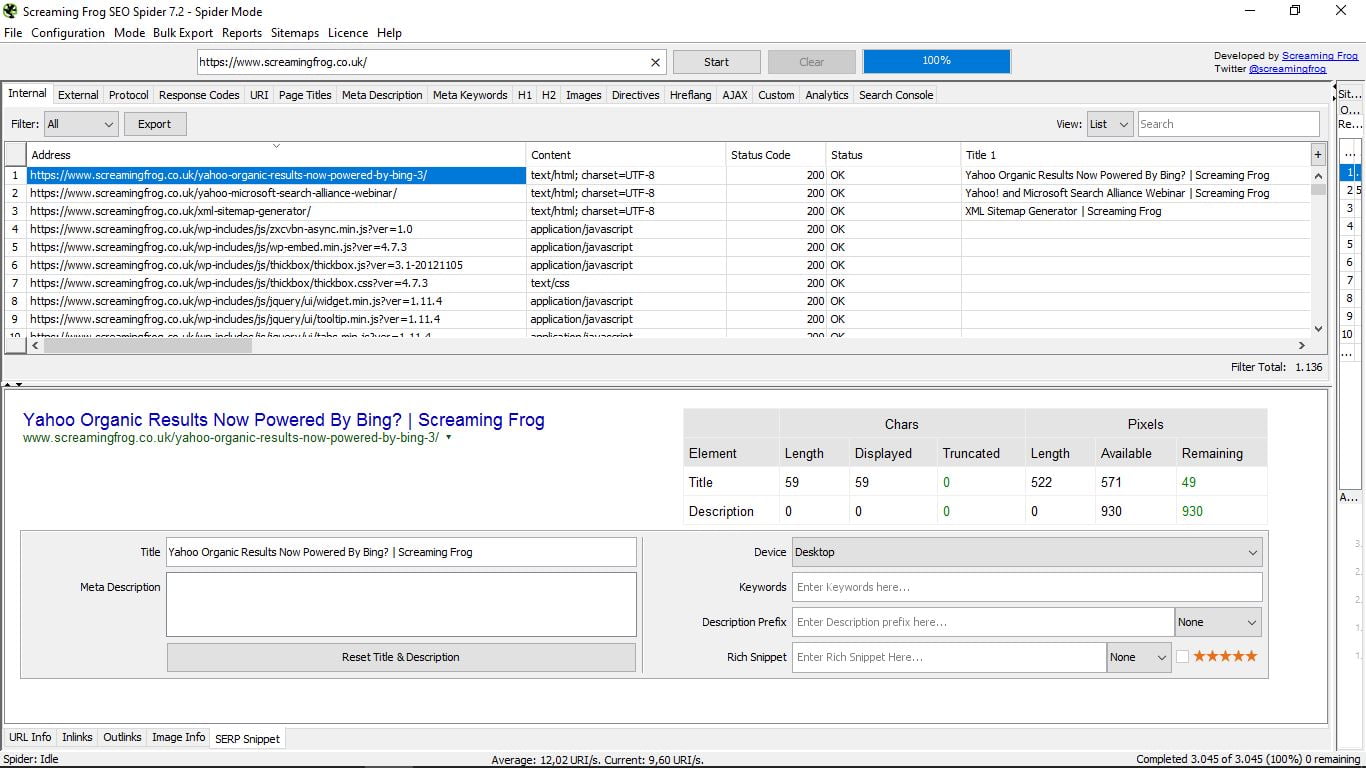
A todo esto, si te fijas, a la derecha de la aplicación, en una estrechita columna que puede ampliarse, tenemos tres opciones que podemos contemplar siempre durante las consultas.

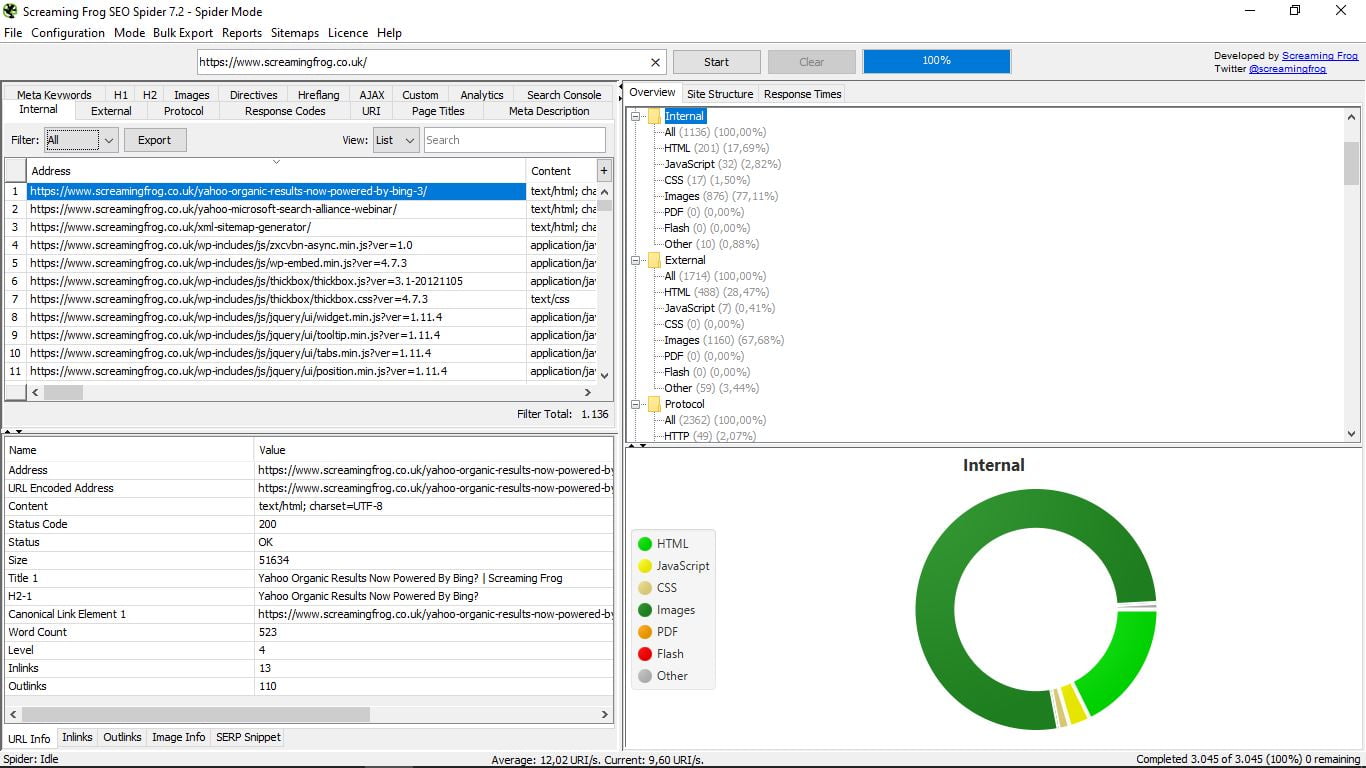
- Overview, una vista general en formato de árbol con carpetas y subcarpetas que nos muestra en cada caso los diferentes componentes de cada información que estamos buscando, con el número total y el porcentaje. Por ejemplo, estando en Internal nos indica, como se puede ver en la captura, que hay un total 1136 páginas, de las que 200 son Html y suponen un 17,69% del total; imágenes hay 876 (77,11%), etc…
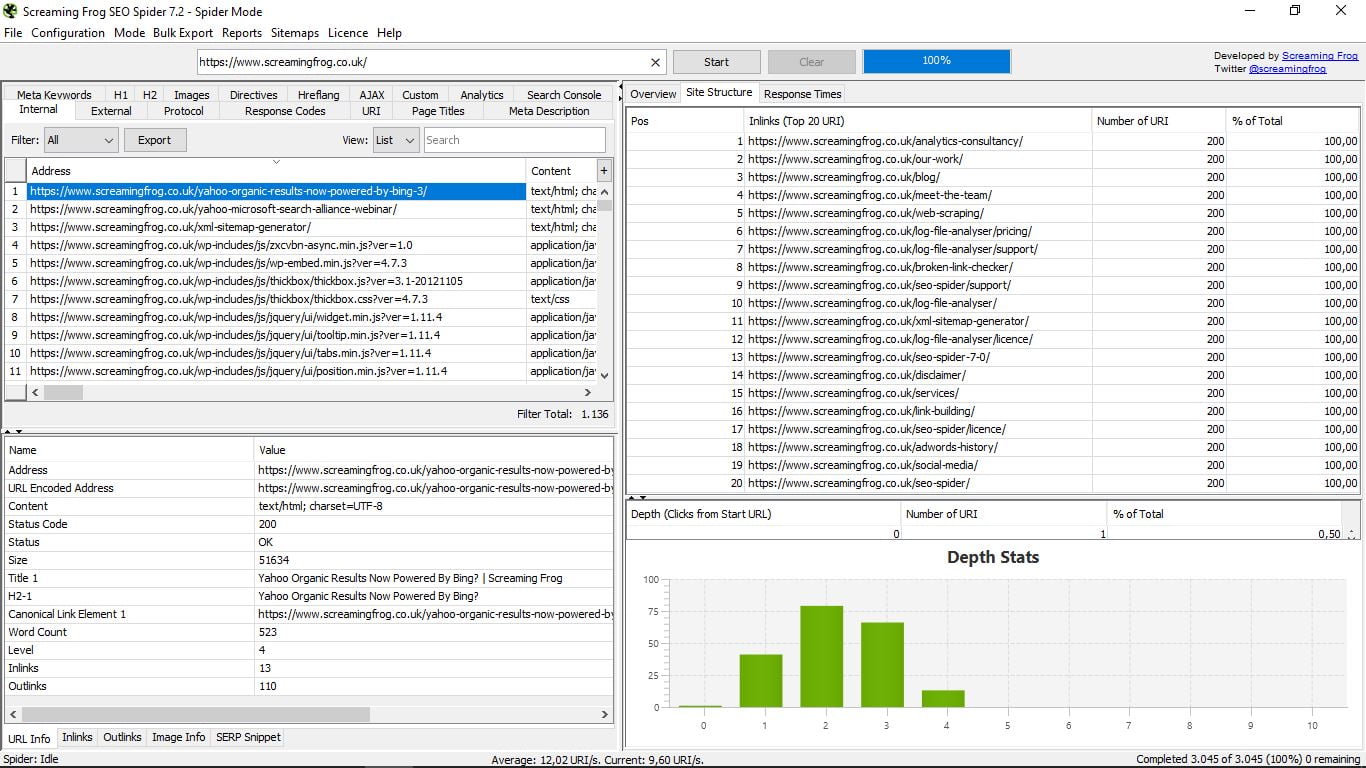
- Site Structure, con la 20 principales urls y las estadísticas de profundidad, esto es, la distancia a la que cada página se encuentra de la url principal o home, que es recomendable que no esté a más de 3 clicks.
- Response Times, que indica los tiempos de carga de cada página por rangos. Hay que intentar que sea siempre el menor posible, pero si pasamos de 4 segundos hay que corregirlo. También vemos el tiempo medio de carga de toda la web.
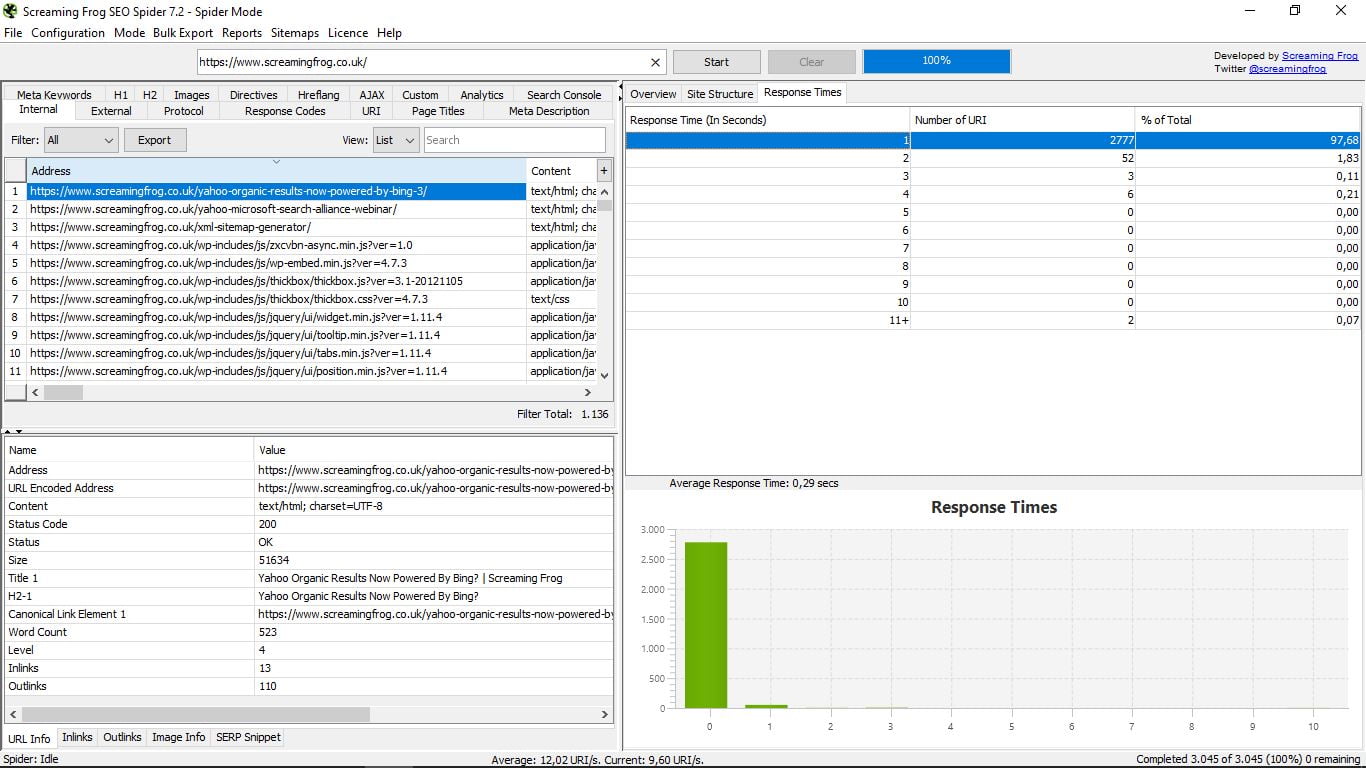
Estas tres funcionalidades, como habrás visto, van acompañadas en la parte inferior por un gráfico. Es el único elemento visual que encontramos en Screaming Frog Seo Spider.
Bien, una vez que hemos visto todas las posibilidades que ofrece la Araña observamos que tenemos hasta 17 apartados donde ver datos específicos de la web indicada.
Hasta ahora estábamos viendo la información de Internal, las páginas internas, que es la opción que viene marcada por defecto. Pero basta con pinchar en cualquiera de las otras opciones para ver lo que nos interese.
3.1 External
Nos lista las páginas externas del dominio de nuestra búsqueda, su tipo (si es Html, imagen, CSS, JavaScript, PDF, Flash, otro…), su código de status (200 Ok, 301, 404…), su nivel y sus enlaces internos.
Recuerda que a la derecha tienes la columna con más opciones generales y sus gráficos, y abajo del todo, las otras cinco funcionalidades para ver información específica de cada una de las urls. Esto es aplicable igualmente para todo lo que vamos a ver.
3.2 Protocol
Vamos a ver las páginas según su protocolo de seguridad (http o https), así como información concreta sobre cada una de ellas (url, tipo de formato, código de status y estado, longitud, enlace canónico principal).
3.3 Response codes
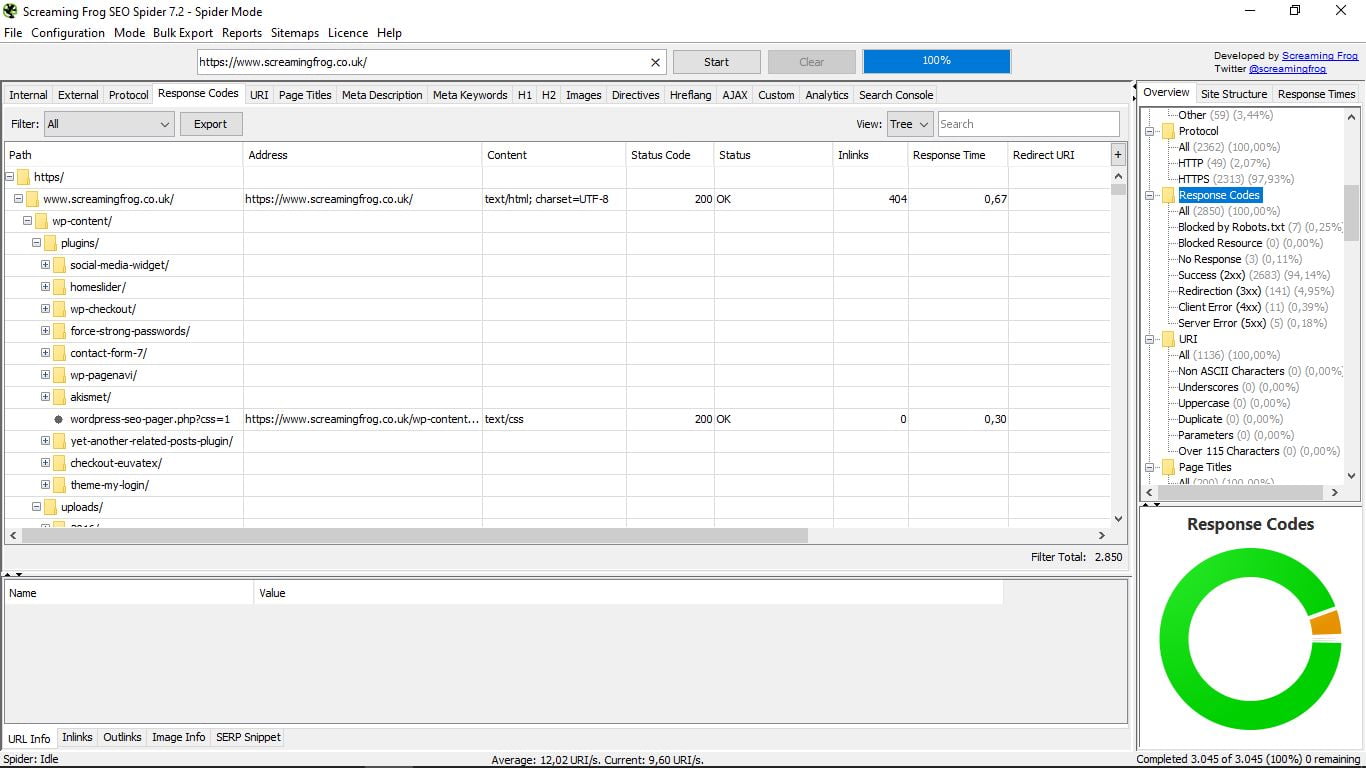
Para ver los códigos de respuesta del servidor es mejor seleccionar la vista de árbol (tree) en lugar de la lista que viene por defecto, como vimos. Así detectaremos mejor las páginas bloquedas por el archivo Robots.txt, los recursos bloqueados, las url que no responden, las que sí, las redireccionadas, y las que dan Client Error y Server Error.
Corregir o eliminar las que dan estos errores 4XX o 5XX es fundamental para tener nuestra página bien optimizada.
3.4 URI
Apartado técnico para ver las direcciones según un identificador de recursos uniforme (URI, del inglés Uniform Resource Identifier): sin caracteres de lenguaje ASCII, subrayados, mayúsculas, duplicados, parámetros y por encima de 115 caracteres.
3.5 Page title
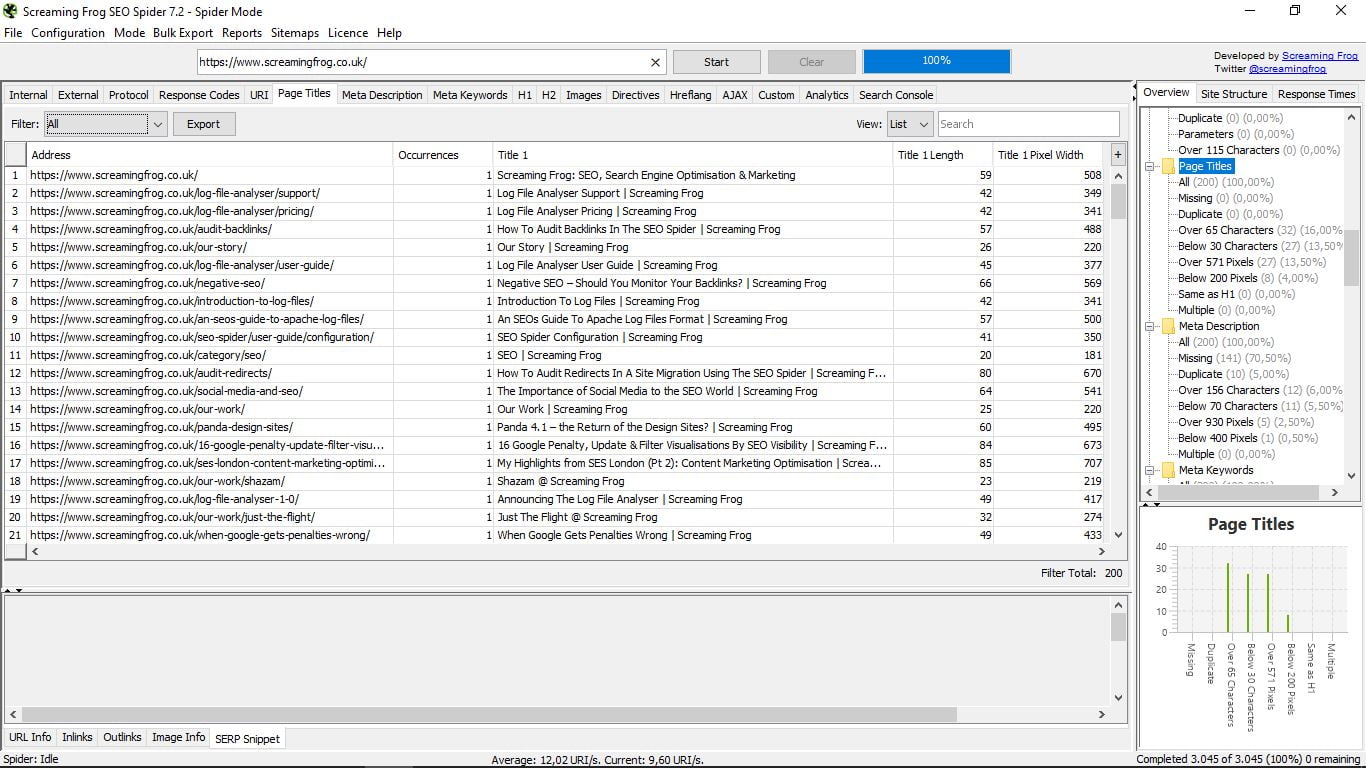
El lugar donde vamos a poder contemplar de un vistazo todos los title de nuestras páginas, su longitud y su ancho en píxels. Útil para detectar páginas sin ellos, o que los tengan duplicados, por encima de 65 caracteres, o por debajo de 30 (topes recomendados por Google); por encima de 571 píxels o por debajo de 200; iguales que el H1; o múltiples.
3.6 Meta description
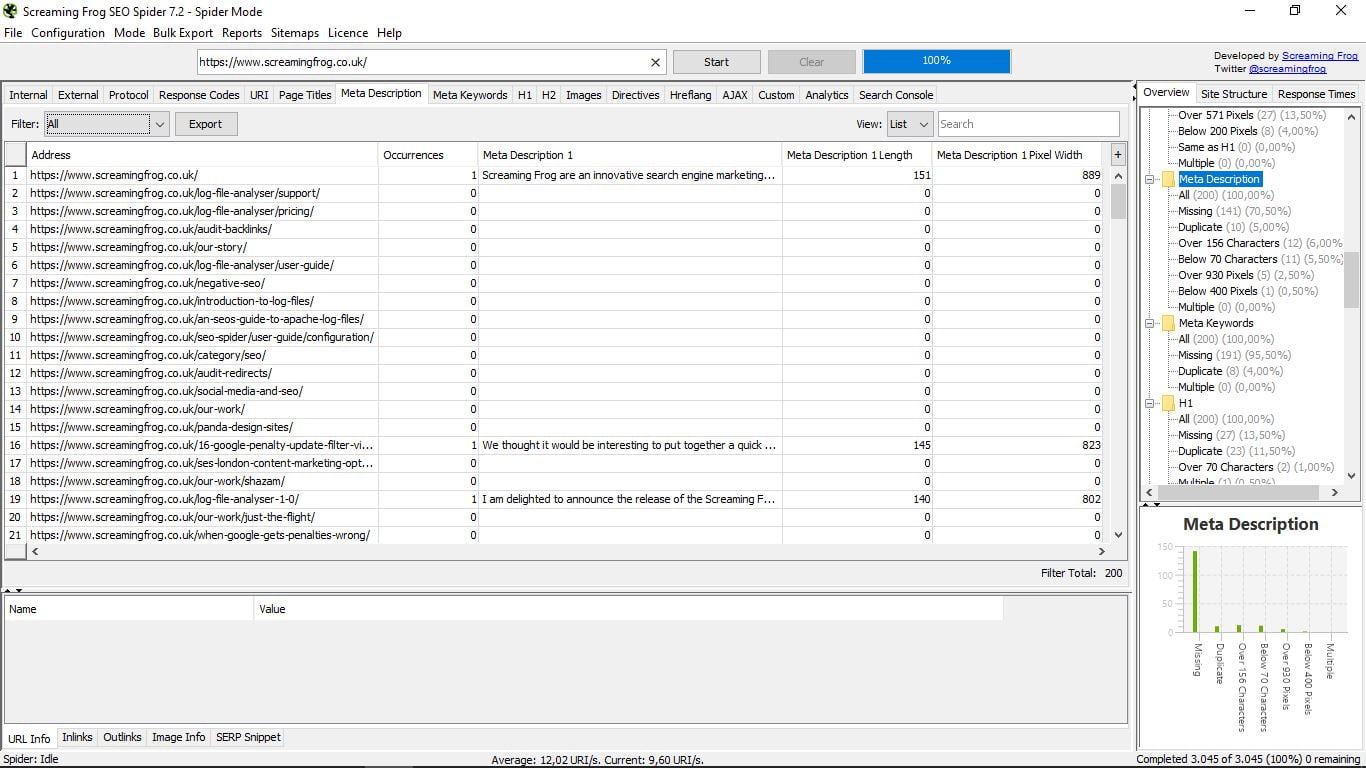
Aquí veremos las metadescripciones de cada una de nuestras páginas, igualmente con su longitud y su ancho en píxels.
Al igual que en el anterior apartado, nos permite ver cuántas páginas no tienen, cuántas las tienen duplicadas, por encima de 156 caracteres o por debajo de 70; o por encima de 930 píxeles y por debajo de 400; y cuántas tienen múltiples.
Recordamos, una vez más, que se pueden filtrar con el “Filter” que hay arriba a la izquierda de la caja con la lista de urls, o bien con la columnita de la derecha.
3.7 Meta Keywords
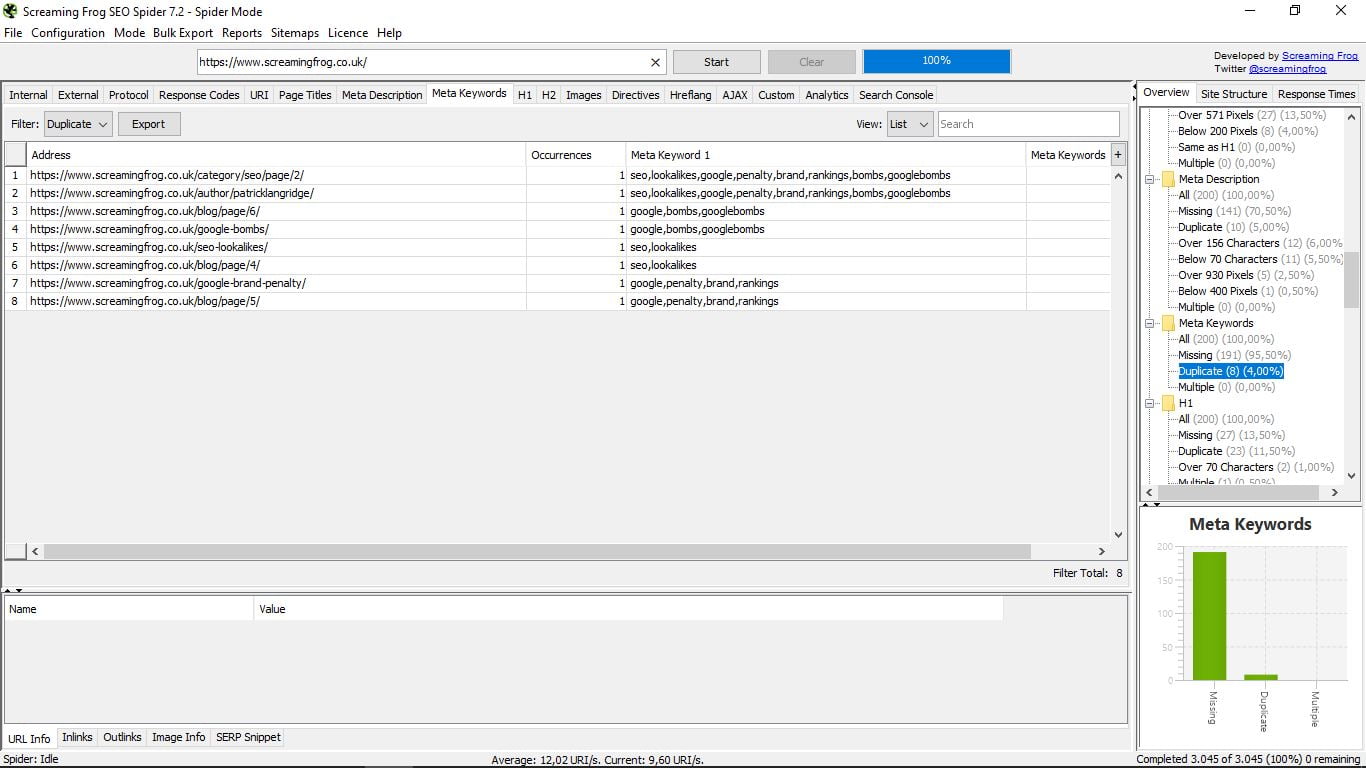
Esta función la verdad es que es obsoleta, ya que desde que Google dejó de tener en cuenta las meta keywords apenas nadie las utiliza. Pero, bueno, ahí está por si alguien tiene la curiosidad de ver en qué páginas y cuáles usa (o usaba, más bien) su competencia.
3.8 Etiqueta H1

Pasamos de un apartado sin utilidad a uno de capital importancia. Aquí se nos muestra los H1 de cada una de nuestras páginas (o de la competencia, según la web de la que hayamos hecho la búsqueda).
Nos indica la longitud en caracteres y si hay más de uno para una misma página (no recomendable). Con la columna de la derecha podemos saber con un simple vistazo cuántas páginas no tienen un H1, cuántos hay duplicados, los que superan los 70 caracteres y los casos múltiples.
3.9 Etiquetas H2

Exactamente lo mismo que el anterior, pero ahora para los H2, donde la diferencia sustancial es que H2 puede haber más de uno sin ningún problema. Aquí se muestran los dos primeros para cada página.
3.10 Images
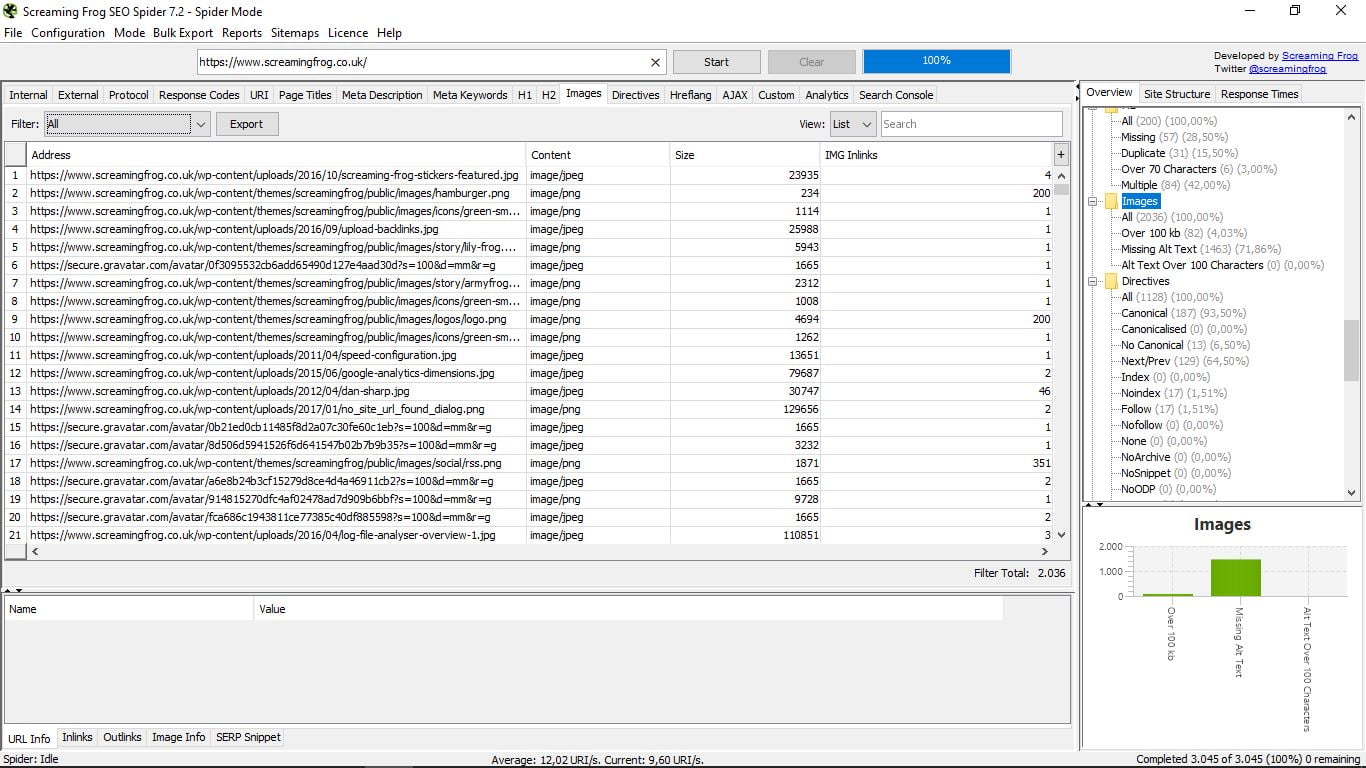
Te radiografía todas las imágenes de la web, indicándote su dirección, su formato (PNG, JPEG…), su peso en Kb, y los links internos. A la derecha o en los filtros podremos buscar las que pesen más de 100 kb, las que no tengan Alt Text o aquellas en que éste supere los 100 caracteres.
3.11 Directives
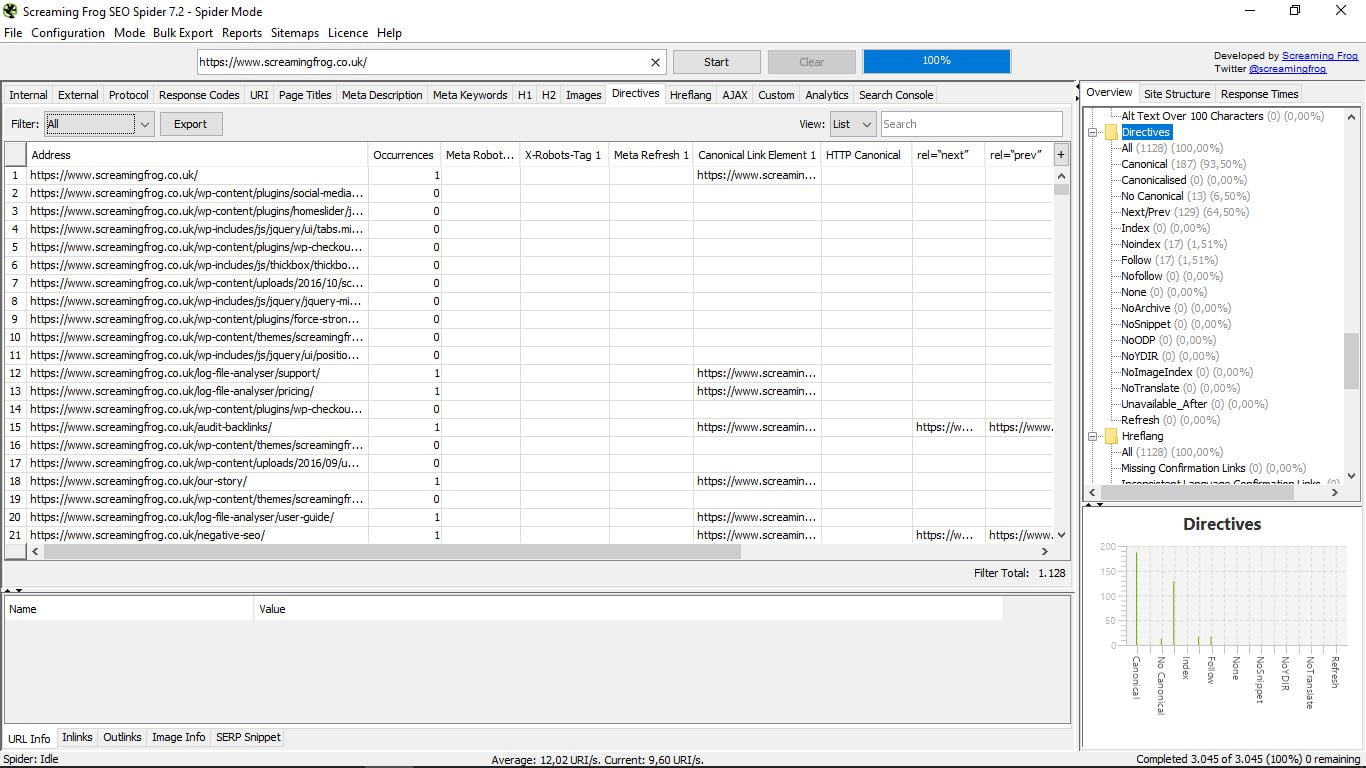
Conoceremos aquí las directivas que rigen para cada página (canonical, next-prev, index/no index, follow/nofollow, no translate…). Puedes consultar la larga lista a la derecha, con sus respectivos porcentaje y el gráfico, o directamente en la caja de la lista de resultados.
3.12 Etiquetas Hreflang
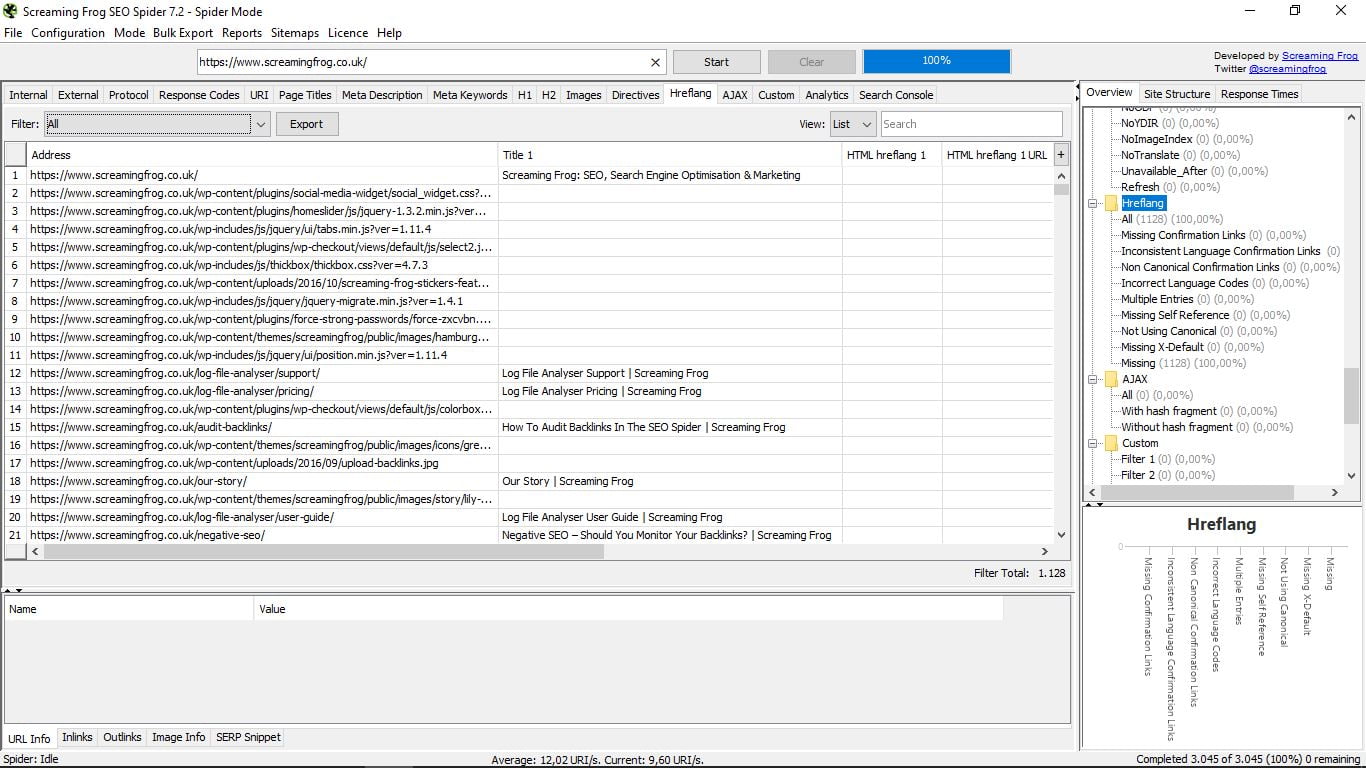
Si has marcado en Google Search Console tu página como multiidioma, tendrás etiquetas Hreflang. Este apartado te las especifica y te avisa de sus posibles errores. Es habitual que la implementación de estas etiquetas dé error.
Aquí verás fácilmente qué falla en cada caso: si no es recíproca, si no existe una canónica o una X-default, etc.
3.13 AJAX
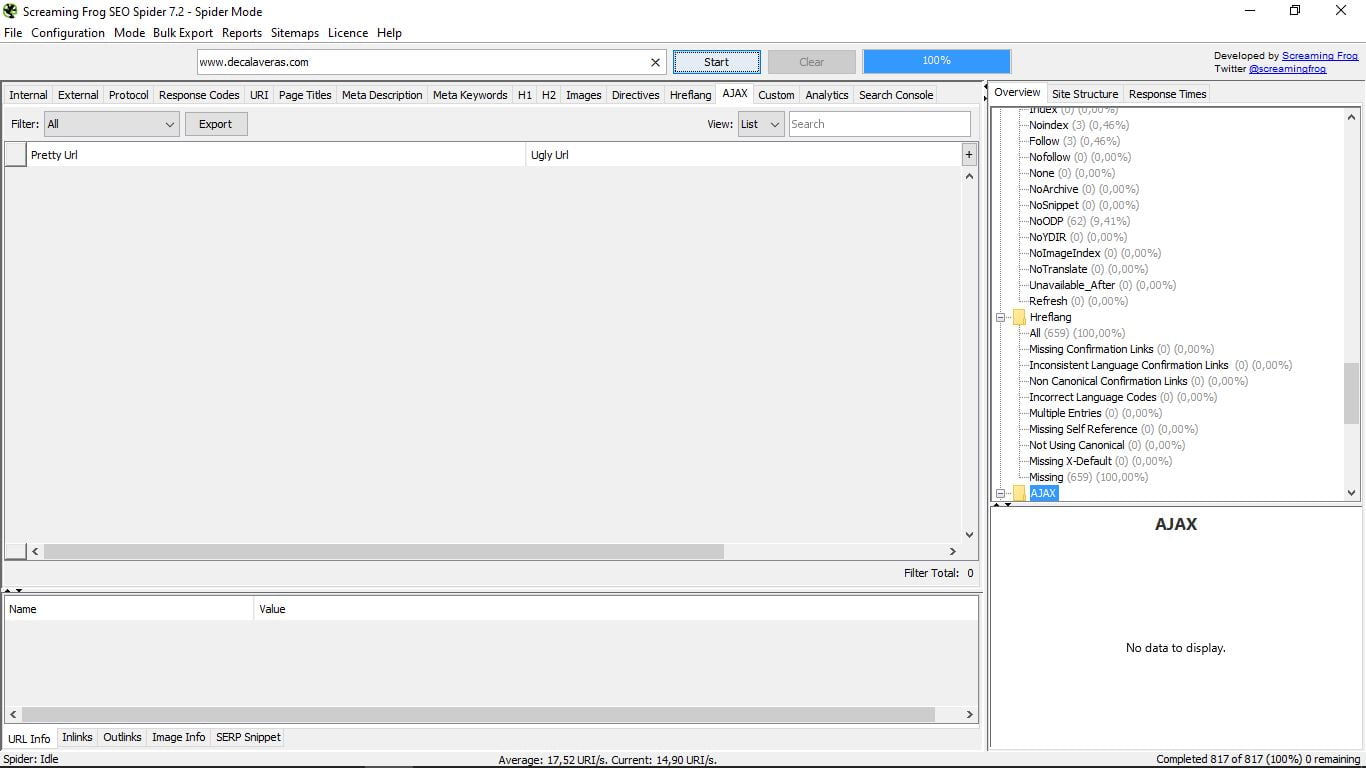
Nada que ver con el detergente ni con el equipo de fútbol de Amsterdam ;_) Son las siglas de Asynchronous JavaScript And XML (JavaScript asíncrono y XML) y se trata de una técnica de desarrollo web que sirve para crear aplicaciones interactivas.
Lo habitual, si tu web es “normal”, es que este apartado esté vacío, como es el caso del ejemplo.
3.14 Custom
Es un apartado para poder realizar búsquedas con filtros personalizados. Para ello hay que configurarlos previamente. Esto se hace en el menú principal “Configuration” y dentro de él en “Custom”:
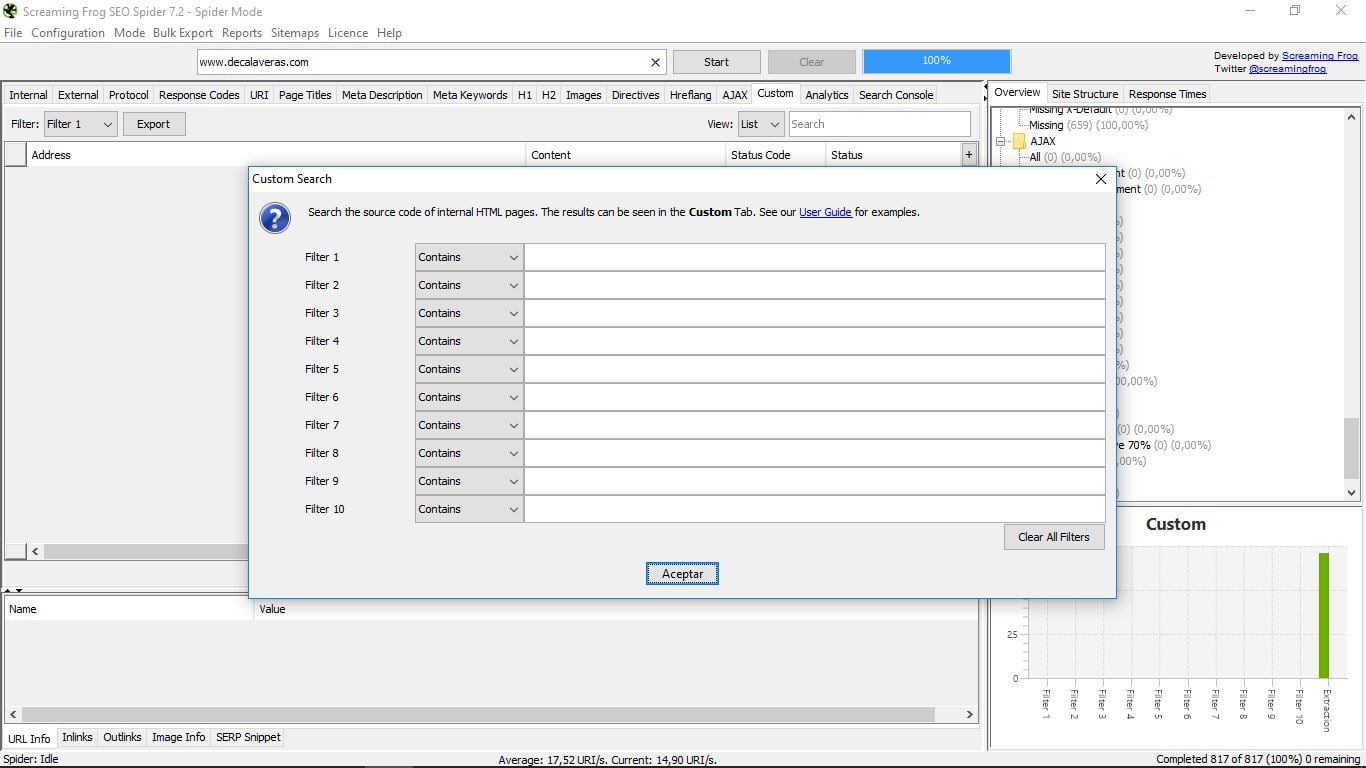
Ahí tenemos la opción de “Search”, es decir búsqueda, o “Extraction”, para obtener determinados elementos de nuestras páginas Html internas. En ambos casos debemos escoger los parámetros que queremos y guardarlos para luego efectuar la búsqueda desde “Custom”.
3.15 Analytics
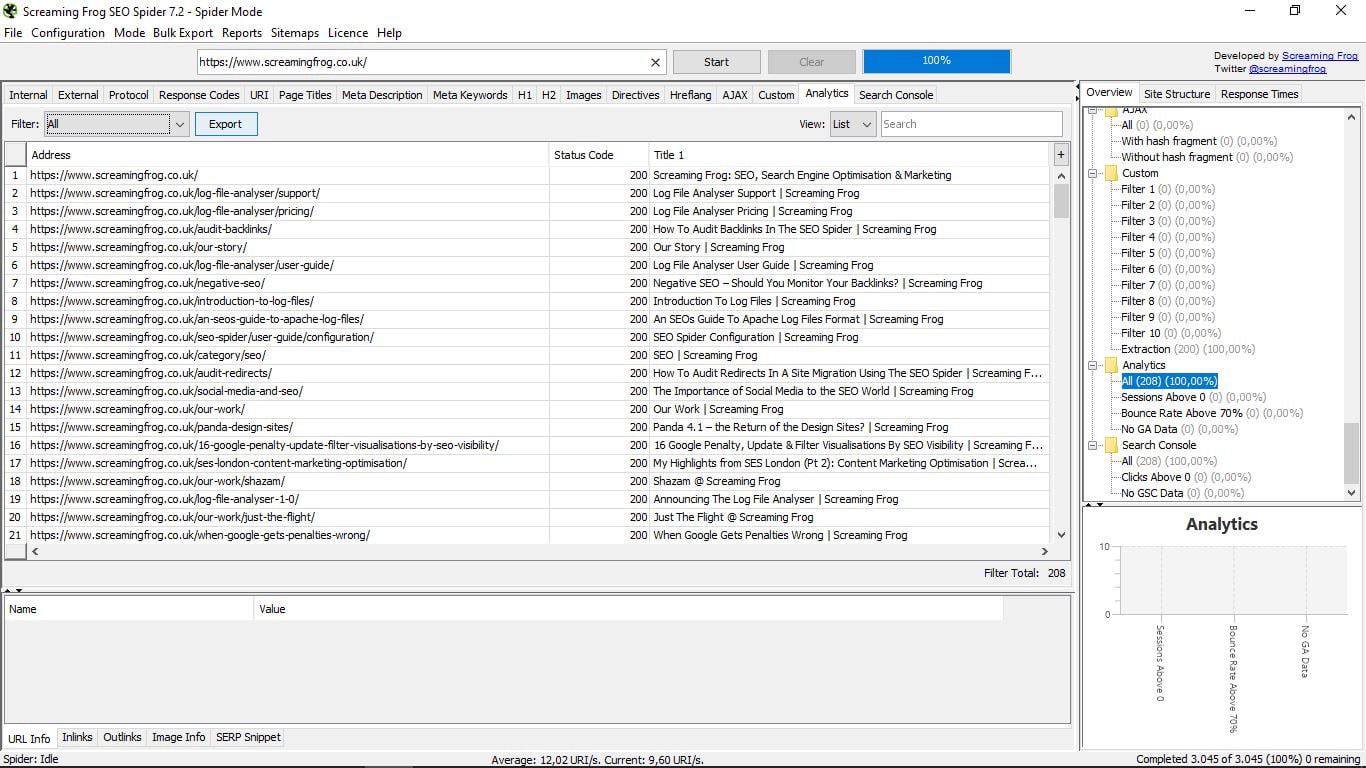
Al conectar la herramienta con Google Analytics podemos ver las sesiones anteriores, las tasas de rebote por encima del 70% o donde no hay datos de Analytics.
3.16 Search Console
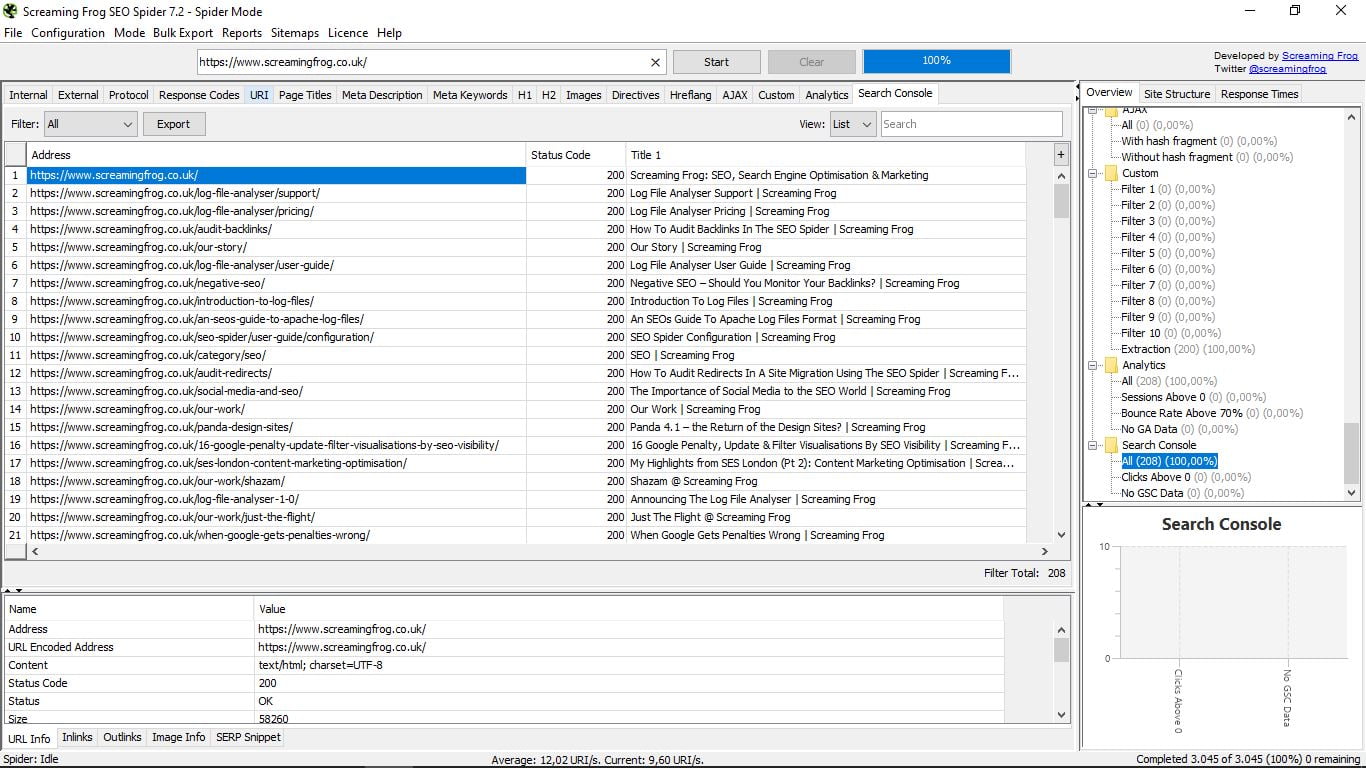
Lo mismo que en el anterior, pero en este caso para la herramienta Google Search Console.
4. Modo List

Aquí lo que nos permite la herramienta es cargar nosotros mismos una lista de urls que tengamos recopiladas en un documento. También cabe la opción de introducirlas a mano, pegarlas o descargarlas de un sitemap o índice sitemap de la url que le digamos.
A partir de ahí, las funciones de la herramienta son exactamente las mismas que en el modo araña.
5. Modo SERP
Esta tercera opción también requiere una carga por nuestra parte, en este caso de un documento CSV con las urls que queremos analizar. Veremos sus title y metadescripciones. El resto de funciones son exactamente iguales que en los dos modos anteriores.
6. Bonus track
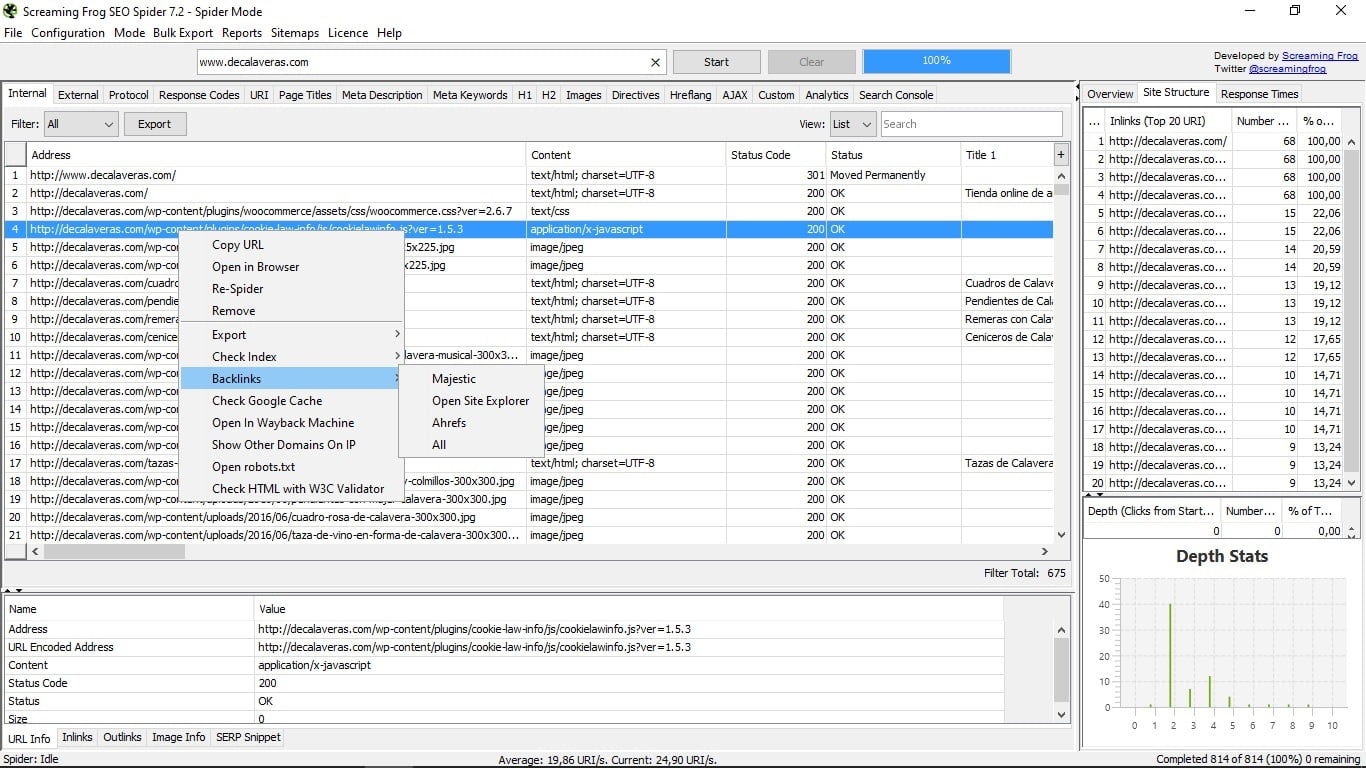
Un truquito de cajón en el que no todo el mundo cae. Si pinchas con el botón derecho en cualquier url, tendrás un menú muy útil donde te permitirá:
- Copiar la url.
- Abrirla en el navegador.
- Hacer que la araña la vuelva a rastrear.
- Borrarla de la lista.
- Exportar la información de esa url, sus links internos, los enlaces externos, datos de sus imágenes y el registro de la ruta de acceso de rastreo.
- Comprobar su indexación en Google, Yahoo, Bing o en todos a la vez.
- Ver los backlinks de esa url a través de las herramientas Majestic Seo, Open Site Explorer y Ahrefs.
- Ver la caché de esa página en Google.
- Abrirla en Wayback Machine, una web que te enseña cómo era una página en los registros históricos que tiene archivados.
- Mostrar otros dominios que están en la misma IP que esa página.
- Abrir el archivo robots.txt que rige esa página.
- Chequear posibles errores de html de la página con la validación de la herramienta W3C.
7. Otras herramientas de Screaming Frog
Screaming Frog también ofrece ahora otras herramientas como el Log File Analyser, un analizador de logs. Esta utilidad te permite cargar tus archivos de registro, identificar las url de rastreo y analizar el comportamiento de la araña, por lo que resulta muy útil para el SEO.
Tiene una versión gratuita y se puede comprar una licencia para disfrutar de todas las funciones adicionales. Pero esta herramienta ya la veremos con detalle en otro tutorial exclusivo.
Cuéntame, ¿tienes dudas sobre Screaming Frog Seo Spider? ¿Es una herramienta que usas?

Muy útil el tutorial y muy currado, gracias! Esperando el de logs… 🙂
Gracias por el Tutorial, recien estoy comenzando con este programa. Después del revisado de mi web, me voy a SERP SNIPPET para cambiar sobre todo los datos de mi home, pero luego… qué tengo que hacer para que queden grabados los cambios? Se que es una pregunta tonta para los expertos, pero, no se guarda si me salgo, tengo que volver a meter los datos. No hay un botón de guardar cambios? muchas gracias amigos
Muy útil el artículo. Me ha encantado. ¡Romuald Fons sigue así!